NVIDIA의 거침없는 진격, 새로운 GPU 플랫폼 「Blackwell」 발표

지난 18일(현지시간), 「GTC 2024」가 미국 캘리포니아주 산호세(새너제이)에서 열렸다. GTC는 NVIDIA(이하 엔비디아)가 AI나 데이터센터용 반도체 등과 관련된 이슈, 신기술, 신제품을 발표하는 정기 이벤트로, 현재 전 세계 산업계의 가장 큰 이슈인 AI 기술을 선도하는 기업 중 하나로 꼽히는 엔비디아의 대형 이벤트인 만큼 GTC 2024는 많은 사람의 관심을 모았다. 그리고 역시나 놀라운 소식이 전해졌다. 어떤 내용인지 함께 살펴보자.

네 줄 요약
- 엔비디아가 A100, H100에 이어 차세대 GPU 「B200」(코드명 Blackwell)을 발표.
- 「B200」은 프로세스 노드 자체의 진화보다 2개의 칩을 하나의 GPU로 동작하게 만듦으로써 성능 향상을 꾀했다.
- 2개의 「B200」과 1개의 CPU를 1개의 모듈로 만든 「GB200」도 공개.
- 엔비디아는 「B200」을 하나의 GPU가 아니라 플랫폼으로 전개해나갈 예정이다.
새로운 GPU 플랫폼 「Blackwell」
생성형 AI 돌풍의 숨은 주역, 엔비디아의 새로운 GPU 「Blackwell」가 GTC 2024 현장에서 정식으로 공개됐다. 생성형 AI의 기초를 닦은 A100, 생성형 AI의 돌풍을 불러오며 몰려드는 주문으로 없어서 못 판다는 최신 성능의 H100에 이은 차세대 AI 칩으로 이전부터 많은 관심을 받았던 바로 그 GPU다.

「Blackwell」의 정식 제품명은 「NVIDIA B200 Tensor Core GPU」로 「Blackwell」은 일종의 코드명이라고 생각하면 된다. 참고로 ‘Blackwell’은 미국국립과학원(National Academy of Sciences)에 흑인 최초로 입회한 수학자(주 분야는 게임 이론과 통계학 전공) 데이비드 해롤드 블랙웰(Davic Harold Blackwell)을 기념하기 위해 붙인 이름이라고 한다.
「Blackwell」은 거대한 2개의 다이(die)가 1개의 패키지에 포함되어 있으며, 2개의 다이는 10TB/s의 NV-HBI로 연결되어 데이터를 주고받으며 1개의 GPU로 동작한다. 192GB 용량의 고대역폭 메모리 HBM3e(8TB/s)를 탑재했고, FP8(Tensor Core)에서 10PFLOPS, FP4(Tensor Core)에서 20PFLOPS 성능을 구현한다.
또한, 칩 사이를 연결하는 NVLink는 5세대로 진화해 대역폭은 1.8TB/s로 넓어졌으며 새로운 NVLink Switch를 이용하면 최대 576개의 GPU가 데이터를 서로 주고받을 수 있다.
2개의 B200과 1개의 Grace(정식 명칭은 NVIDIA Arm CPU)를 1개의 모듈로 만든 「GB200」도 함께 공개됐다. 「GB200」은 현재 최신 제품인 H100과 비교하면 AI 학습 시 성능은 4배, 추론 시 성능은 30배까지 높아졌으며, 전력 효율도 25배 개선됐다고 엔비디아는 설명하고 있다.

압도적인 성능의 「Blackwell」
엔비디아가 GTC 2024에서 발표한 「NVIDIA B200 Tensor Core GPU」(코드명 Blackwell, 이하 B200)은 엔비디아가 2022년에 발표한 「Hopper」(정식 명칭은 NVIDIA H100 Tensor Core GPU)(이하 H100)의 후속 제품으로 일반 소비자용이 아니라 AI, 데이터센터용 GPU다.
「B200」의 가장 큰 특징은 1개의 패키지에 2개의 거대한 다이가 수납되어 있다는 점이다. 어떤 기술을 이용해 2개의 다이를 1개의 패키지에 수납했는지는 공개하지 않아 지금으로서는 알 수 없지만, 레고를 차곡차곡 쌓아가는 것처럼 하나의 칩에 여러 칩을 집적하는 ‘chiplet’ 관련 기술이 적용되지 않았나 짐작된다. 칩 사이의 연결에는 NV-HBI라는 독자적인 기술이 적용되어 10TB/s라는 놀라운 초광대역으로 연결된다.
제조에 이용된 프로세스 노드는 TSMC의 4NP로 H100 제조에 이용된 동사의 4N 공정을 개량한 것이다. 즉, 프로세스 노드의 변화에 따른 성능 향상은 미약한 수준으로, 2개의 다이를 1개의 패키지로 만들어 성능 향상을 꾀했다는 점이 핵심이라 생각하면 된다.
사용되는 칩이 2개로 늘어나면서 메모리 컨트롤러의 수도 2배로 늘어났고, 이에 따라 탑재할 수 있는 메모리 용량도 늘어났다. H100에서는 80GB의 HBM3가 사용됐는데, B200에서는 192GB의 HBM3e가 탑재됨과 동시에 메모리 대역폭도 3.35TB/s(H100)에서 8TB/s(B200)로 2배 넘게 대역폭이 늘어나면서 성능 향상에 크게 영향을 끼친 것으로 보인다.
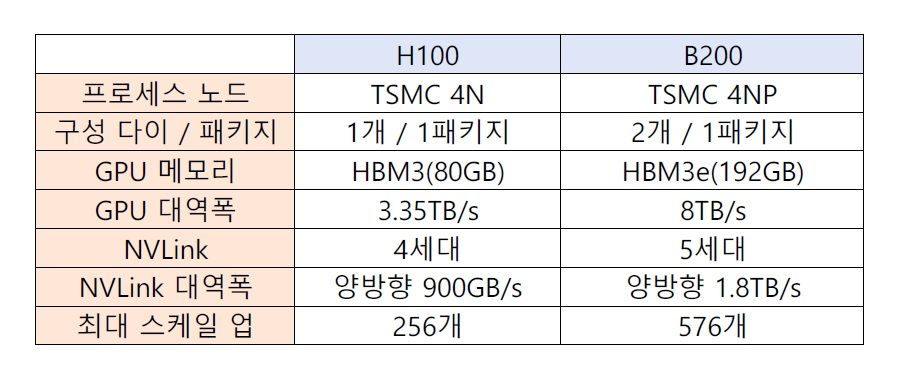
종합적인 성능은 얼마나 높아졌을까? 엔비디아 발표한 자료를 보면 FP8(Tensor Core)의 성능은 10PFLOPS다. 이는 H100의 FP8(Tensor Core)의 약 4PFLOPS와 비교하면 약 2.5배 높은 수치다. 참고로 B200은 H100은 대응하지 않았던 FP4(Tensoer Core) 연산에도 대응할 수 있게 되어, AI 추론 시 FP4를 이용하면 20PFLOPS의 성능을 실현할 수 있다고 한다. 만약 AI 추론 시 FP8이나 INT8 등으로 변환해 FP4로 연산하면 H100의 약 5배에 해당하는 추론 성능을 구현할 수 있다는 뜻이다.
칩 사이를 연결하는 NVLink의 진화도 눈여겨볼 부분이다. 4세대 NVLink가 적용된 H100은 양방향으로 900GB/s의 대역폭을 지원했는데, 5세대 NVLink가 적용된 B200은 양방향으로 1.8TB/s로 대역폭이 2배 확장됐다. 그리고 5세대에 대응하는 NVLink Switch를 이용하면 최대 576개의 GPU가 데이터를 서로 주고받을 수 있다.

이밖에 신뢰성을 검증하는 RAS 엔진과 TEE 등의 컨피덴셜 컴퓨팅 기능, 데이터 복원용 액셀러레이터로 작용해 데이터베이스 쿼리를 고속화하는 Decompression 엔진 등을 탑재해 데이터센터를 운영하는 기업의 생산성 향상을 지원한다.
수퍼칩 「GB200」도 함께 공개
「B200」과 함께 「NVIDIA GB200 Superchip」(이하 GB200)도 공개됐다. 「GB200」은 2023년 열린 COMPUTEX 23에서 발표한 ‘Grace Hopper’(정식 명칭은 NVIDIA GH200 Superchip, 이하 GH200)의 후속 제품으로 그동안 코드명 ‘Grace Blackwell’로 불려왔다.
「GH200」은 Arm CPU인 Grace(Neoverse V2 CPU) 1개, H100 1개를 하나의 모듈로 제공했는데, 「GB200」은 Grace 1개, B200 2개를 하나의 모듈로 제공한다. CPU가 1개인 점은 그대로지만, GPU가 2개로 늘어나며 성능이 크게 높아졌다. 엔비디아의 설명에 따르면 「GB200」의 성능은 H100과 비교해 AI 학습 시에는 4배, AI 추론 시에는 30배, 전력 효율은 25배 향상됐다고 한다.
엔비디아는 B200, GB200, NVLink, NVLink Switch를 이용한 스케일 업, 그리고 각종 네트워크 솔루션을 이용한 스케일 아웃을 통해 다양한 서버 종류, 수퍼 컴퓨터 구성을 선보였다.

「DGB B100」은 8GPU 구성의 서버 기기 「DGX H100」의 후속 모델로 2개의 5세대 Xeon 프로세서와 8개의 B200을 탑재해 144PFLOPS의 AI 성능을 제공한다.
「DGX H100」과 비교하면 1조 개의 파라미터 모델에 의한 AI 추론 성능은 15배 높아졌다고 엔비디아는 설명한다. 「DGX B200」의 OEM판인 「HGX B200」도 준비되어 있다.
「GB200」 모듈을 2개 탑재한 블레이드 서버 18대로 구성된 랙 타입의 「GB200 NVL72」도 발표했다. 「GB200 NVL72」 1대에는 최대 36개의 Grace CPU, 72개의 B200 GPU가 수납된다. 수냉식 냉각 시스템을 채용했으며 총 1,400TFLOPS(1.4EFLOPS)의 성능을 자랑한다. 「GB200 NVL72」은 클라우드 서비스 프로바이더에 납품될 예정으로 AWS, Google Cloud, Oracle Cloud가 도입할 예정이다.

「GB200 NVL72」와 같은 성능의 「DGX GB200」을 8개 연결한 「DGX Super POD」도 발표됐다. 여기에는 288개의 Grace CPU, 576개의 B200이 1개의 POD로 구성된 수퍼 컴퓨터로 전체 시스템은 240TB 메모리, FP4(Tensor Core) 이용 시 최대 11.5EFLOPS의 성능을 구현한다.

엔비디아는 B200, GB200을 탑재한 시스템은 2024년 중에 출시될 예정이며 AWS, Google Cloud, Oracle Cloud, Microsoft Azure 등의 클라우드 서비스 프로바이더를 비롯해 Cisco, Dell Technology, HPE, Lenovo, Supermicro 등의 서버 공급사에 납품할 예정이라고 밝혔다.
B200, GB200 등의 가격은 공개되지 않았지만, B200의 가격은 H100의 약 4만 달러보다 최소 1만 달러 이상 비싸질 것이라는 전망이 애널리스트와 미디어 사이에서 나오고 있다.




