인공지능 학습의 새로운 주역, NPU

전통적인 PC 사용자들에게 익숙한 CPU, GPU 개념에 더해 최근에는 ‘NPU’라는 개념이 새로 등장해 많이 사용되고 있다. 특히 ChatGPT의 등장으로 생성형 AI가 주목을 받으면서 생성형 AI를 학습시키는 용도로 NPU가 많이 언급되고 있다.
글이 주류였던 과거와는 달리 지금은 이미지나 영상을 통한 지식 획득이 더 일반적이다. 그리고 이미지나 영상을 디지털로 표현하려면 훨씬 더 많은 데이터 용량이 필요해진다. 그래서 생성형 AI에게 다양한 유형의 대용량 데이터를 학습시키고 이를 바탕으로 명령 입력을 실시간으로 처리하려면 기존 기술로는 대응이 어려워지는데, 높은 연산 능력과 효율성으로 이를 해결하는 새로운 기술이 등장했다. 데이터 시대를 선도하는 차세대 반도체 중 하나인 NPU가 바로 그 주인공이다.
이번 기사에서는 NPU는 구체적으로 무엇을 의미하는지, 어떤 역할을 하는지 등을 살펴보고자 한다.

세 줄 요약
- NPU는 인공지능 학습을 효율적으로 수행하기 위해 태어났다.
- NPU는 GPU보다 AI 학습 능력 자체는 뒤지지만, 비용을 낮출 수 있고 에지 디바이스에서 장착하기도 쉽다.
- 최근 주목받는 온디바이스 구상의 중추 역할을 맡고 있다. AI 이용을 위해 외부와 통신할 필요가 없으므로 안전성이 높다.
NPU란 무엇인가?
사람의 몸에서 자극을 받아들이고 적절한 판단을 기반으로 반응 신호를 보내는 체계를 신경계(Neural)라고 한다. 뇌는 감각기관에서 받은 자극을 종합적으로 판단하고 명령을 내리는데, 사람의 뇌처럼 정보를 받아들이고(학습하고) 반응 신호를 보내는(처리하는) 프로세서를 신경망 처리 장치(Neural Processing Unit), 즉 NPU라고 부른다.
NPU는 많은 신경 세포와 시냅스로 연결되어 신호를 교환한다. 인간의 뇌 신경 세포가 동시에 작업을 수행하는 것과 유사하다. NPU에는 스스로 학습하고 판단할 수 있는 인공 지능(AI) 기술이 적용되기 때문에 NPU를 AI 칩이라고도 부른다.
기존의 컴퓨터에서는 중앙 처리 장치(Central Processing Unit, CPU)가 이러한 기능을 담당해왔다. CPU는 모든 데이터를 처리하는 연산 능력을 갖추고 있지만, 반복되는 간단한 작업을 처리하기엔 적합하지 않다. 미처 그 능력을 다 쓰지 못하기 때문이다. 3억짜리 스포츠카 사서 집 앞 편의점에만 타고 다니는 격이랄까?
이에 비해 NPU는 다중 작업 행렬 연산에 최적화된 프로세서라서 실시간으로 여러 연산을 처리하기에 적합하다. 또한, 축적된 데이터를 기반으로 스스로 학습하고 최적의 값을 끌어낸다. 이런 특징 덕분에 NPU는 컴퓨터가 인간처럼 생각하고 학습하는 딥 러닝처럼 머신 러닝(기계 학습)에 적합한 기술로 평가된다.

생성형 AI가 주목을 받으면서 이를 학습시키기 위한 대규모 언어 모델, 고대역폭 메모리, 신경망 처리 장치 등 관련 기술이 최근 등장했다고 생각하기 쉽지만, 사실 상당히 오래전부터 개념이 확립됐으며 개발이 진행되고 있었다. 고대역폭 메모리(HBM)는 2013년에 SK하이닉스에 의해 최초로 발표된 메모리 규격이며, NPU 역시 삼성전자가 2018년 11월에 공개한 모바일 애플리케이션 프로세서(Application Processor, AP)인 「Exynos 9」(9820)에 이미 탑재될 정도로 활발히 사용되고 있었다. 참고로 「Exynos 9」은 기존 제품(9810) 대비 약 7배 빠른 인공지능 연산 능력을 갖추어 화제가 되기도 했다.
NPU의 고속 연산은 증강 현실(AR)이나 가상 현실(VR)처럼 인물과 물체의 특징을 빠르고 정확하게 인식하여 생동감과 즐거움을 제공하는 사용자 경험(User Experience) 기술에서 효과적으로 발휘된다. 또한, 기존에는 서버와 연결되어 수행되던 인공지능 연산 작업이 이제는 모바일 장치 단독으로도 가능해져 보안 측면에서도 개선됐다.

NPU의 등장 이유
NPU란 무엇이고, 어떤 역할을 하는지 살펴보았다. 그럼 여기서 한 가지 근원적인 물음이 생긴다. 어쩌다 NPU가 등장하게 된 걸까? 기사를 자세하기 읽어보았다면, ‘NPU는 다중 작업 행렬 연산에 최적화된 프로세서라서 실시간으로 여러 연산을 처리하기 적합하다’를 해답으로 제시할 것이다. 틀리지는 않았다. 하지만 충분한 대답은 아니다.
기억력이 좋은 독자라면 이전 GPU 관련 기사에서 AI 학습을 위한 딥 러닝에 GPU가 적합하다고 언급했던 걸 떠올릴 수 있을 것이다. AI 학습을 위해 더 적합한 방법(GPU를 이용한 방법)이 있는데 왜 NPU가 등장한 것일까? 성능도 GPU가 NPU보다 뛰어나니 AI 학습에 더 유리할 텐데?
성능은 GPU가 NPU보다 훨씬 우월
GPU는 연산 능력의 지표인 ‘부동소수점 곱셈’을 매우 빠르게, 느리고 많이 처리할 수 있는 유닛이다. 즉, 딥 러닝이나 AI 학습에 유리하다. 그러나 이 능력을 살리기 위해서는 어떻게 계산하고 어떻게 처리할 것인지 GPU에 지시를 내리고 컨트롤하는 뒷받침이 필요하다. 엔비디아는 GPU를 이용한 이런 과정이 원활하게 진행될 수 있도록 CUDA 기술을 제공한다. 간단히 말해 CUDA는 GPU의 연산을 효율적으로 컨트롤할 수 있는 일종의 소프트웨어 개발 킷이라 생각하면 된다. CUDA를 이용하면 GPU를 통한 연산을 아주 효율적이고 유연하게 관리할 수 있다.

NPU는 GPU와 CUDA가 함께 구현한 GPU 연산 네트워크의 일부를 물리적으로 구현한 칩셋이다. 따라서 입력한 명령이 NPU가 구현한 신경망 내에서 처리할 수 있는 내용이라면 효과적이고 빠르게 수행할 수 있지만, NPU 내에서 구현되지 못한 내용이라면 NPU가 아닌 CPU 내에서 처리되어야 한다. 즉, 속도가 느려지게 되는 것이다. GPU라면 CUDA를 통해 네트워크 구성을 조절하면 처리할 수 있지만, NPU는 물리적으로 네트워크 일부를 구성한 것이므로 유연한 대응이 어려워진다.
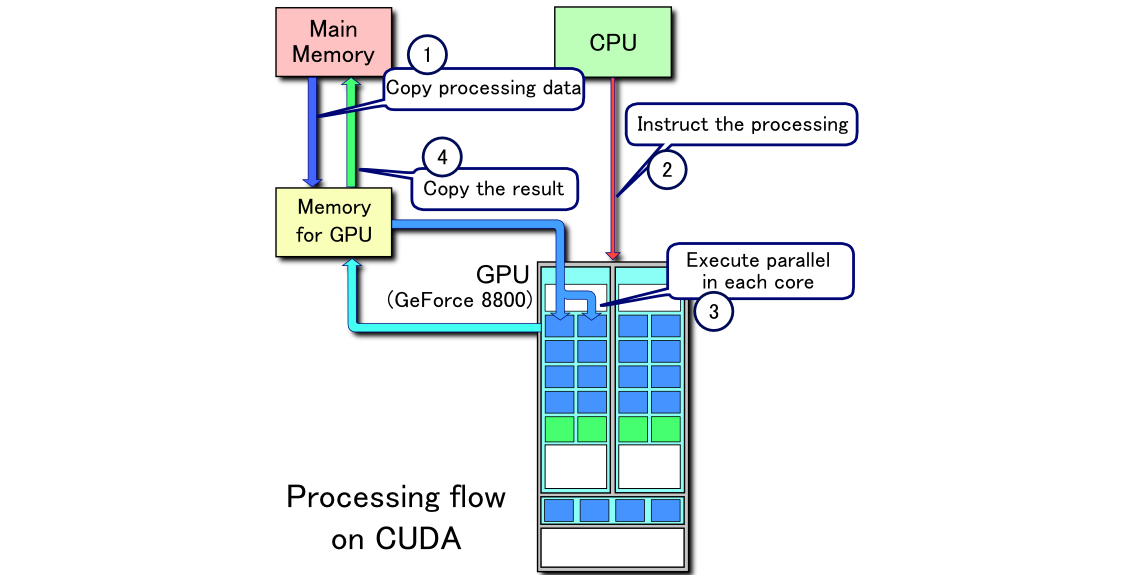
그럼에도 NPU가 주목받는 이유
성능 면에서 GPU보다 떨어지고 유연한 대응도 불가능한 NPU가 왜 요즘 들어 주목받고 있을까? 첫 번째는 GPU를 이용한 AI 학습이 너무 비싸기 때문이다.
고성능 GPU와 고대역폭 메모리를 이용한 현재의 AI 학습법은 비싸다는 점만 빼면 단점이 없다. 더 많은 정보를 빠르게 학습할 수 있다는 말은 AI의 성능이 그만큼 좋아진다는 말이고, CUDA를 이용해 소프트웨어 라이브러리를 구현하면 네트워크 구성도 유연해진다. 그런데, 이 과정을 스마트폰, 태블릿, 노트북 등에서 실현할 수 있을까?
GPU를 이용한 기존 방식은 가격도 문제지만, 전력 소비나 발열 등의 문제로 인해 휴대가 어렵다. 스마트폰에 데스크톱용 그래픽카드를 넣는다고 생각해보자. 이해가 쉬울 것이다. 그렇다고 모바일 프로세서에 포함된 CPU만으로 AI 학습을 시도한다면? 답답한 속도로 인해 속이 터질 것이다. 배터리도 금방 방전될 것이고. 그렇기에 비록 절대적인 성능은 떨어지지만 NPU를 통해 AI 학습에 대응하는 것이다.

두 번째는 에지 디바이스의 활용도를 높이기 위해서다. 대규모 언어 모델(LLM)이 AI 학습에 적용되면서 이제는 글뿐만 아니라 이미지나 영상을 통해서도 AI가 학습하고 있으며, 사용자 역시 프롬프트 입력에 더해 이미지나 영상을 데이터로 제공해 AI 기능을 활용한다.
따라서 정보를 서버나 클라우드에 보내서 처리하고 다시 결과물을 받는 과정보다는 사용자가 직접 이용하는 에지 디바이스에서 해당 과정을 직접 처리하는 것이 작업 속도와 효율성 면에서 우수하다. 즉, AI 학습은 서버나 클라우드 등 중앙 장비에서 담당하고, AI 활용은 에지 디바이스, 즉 말단 장비에서 담당하는 것이다. 이 방식(온디바이스)은 외부와 통신으로 연결될 필요가 없으므로 사용자의 데이터가 외부로 누출될 염려가 크게 줄어든다는 장점도 있다.



