똑똑한 AI의 비결, 인공신경망이 학습하는 딥 러닝

지난 기사에서 AI의 학습 방법 중에서 데이터를 분석하고 그 안에서 패턴을 찾아내어 예측하는 인공 지능의 한 형태(알고리즘), ‘머신 러닝(Machine Learning)’에 대해 살펴보았다. 이번 기사에서는 머신 러닝과 함께 AI의 대표적인 학습 방법으로 꼽히는 딥 러닝(Deep Learning)에 대해 살펴보려 한다.
세 줄 요약
- 딥 러닝은 레이블(정답)을 제공해주는 머신 러닝과 달리 인공 지능이 특징을 추출할 수 있도록 신경망을 주고, 인공 지능은 많은 데이터를 기반으로 스스로 특징을 종합해 판독한다.
- 딥 러닝의 기술적인 특징은 계층 학습을 사용하여 먼저 하위 수준의 특징을 식별한 다음 이를 기반으로 상위 수준의 특징을 식별한다는 점이다.
- 딥 러닝의 대표적인 예는 이미지를 판독하고 식별하는 데 사용하는 합성곱 신경망이다.
뇌의 작동 원리에서 영감을 받은 딥 러닝
딥 러닝은 머신 러닝의 하위 분야로, 뇌의 작동 원리에서 영감을 받아 지식을 얻기 위한 알고리즘에 중점을 두고 있다. 그래서 심층 구조 학습(Deep Structured Learning) 또는 계층 학습(Hierarchical Learning)으로도 불린다. 이해를 돕기 위해 딥 러닝의 정의로 가장 널리 알려진 내용 중 하나를 소개한다.
“딥 러닝은 데이터 사이의 복잡한 관계를 모델링하기 위해 다중 수준의 표현을 학습하는 알고리즘을 기반으로 하는 기계 학습의 하위 분야다. 상위 레벨의 특징과 개념은 하위 레벨의 특징을 기반으로 정의되며, 이러한 특징의 계층 구조를 ‘심층 아키텍처’(deep architecture)라고 한다.” - 출처 : “Deep Learning: Methods and Applications”
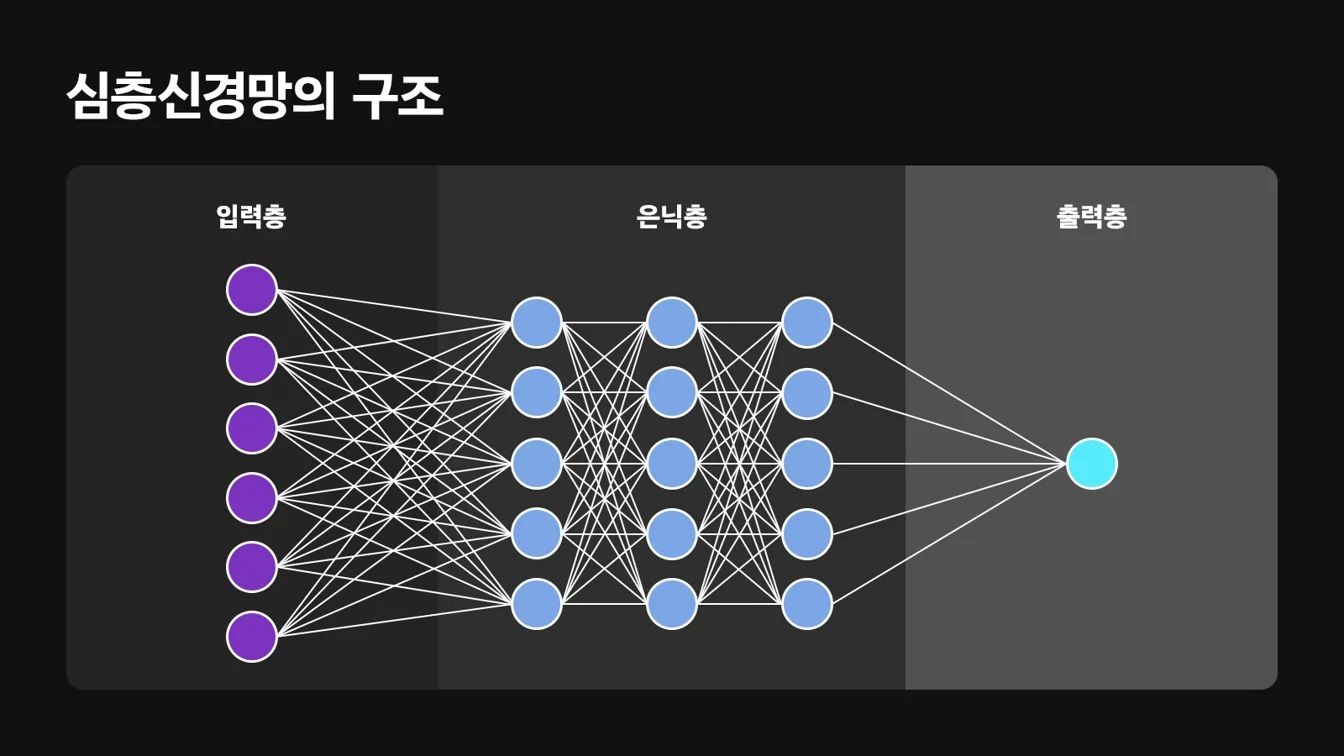
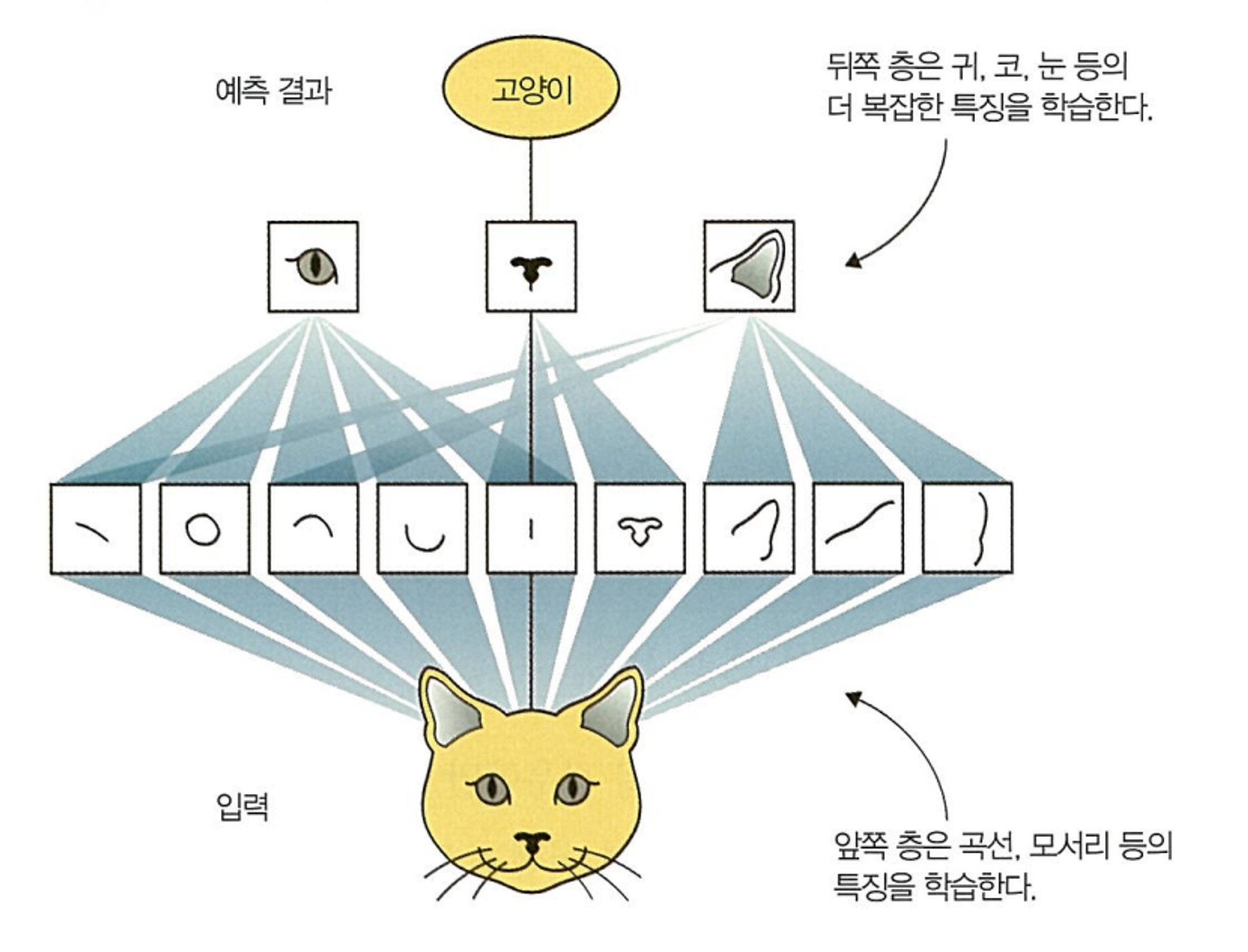
딥 러닝은 인공 신경망(ANNs)의 개념을 기반으로, 네트워크를 깊게 만들어 많은 양의 데이터를 처리할 수 있도록 확장한다. 이 신경망은 인간의 뇌에 있는 신경 세포(뉴런)를 모방한 구조로 여러 레이어로 이루어져 있다. 여러 레이어를 가진 딥 러닝 모델은 원본 데이터에서 특징을 추출하고 각 레이어에서 이러한 특징을 점진적으로 ‘학습’하는데, 이러한 기법을 계층적 특징 학습이라고 하며, 인간의 개입을 최소한으로 줄인 채 복잡한 특징을 자동으로 학습할 수 있다.
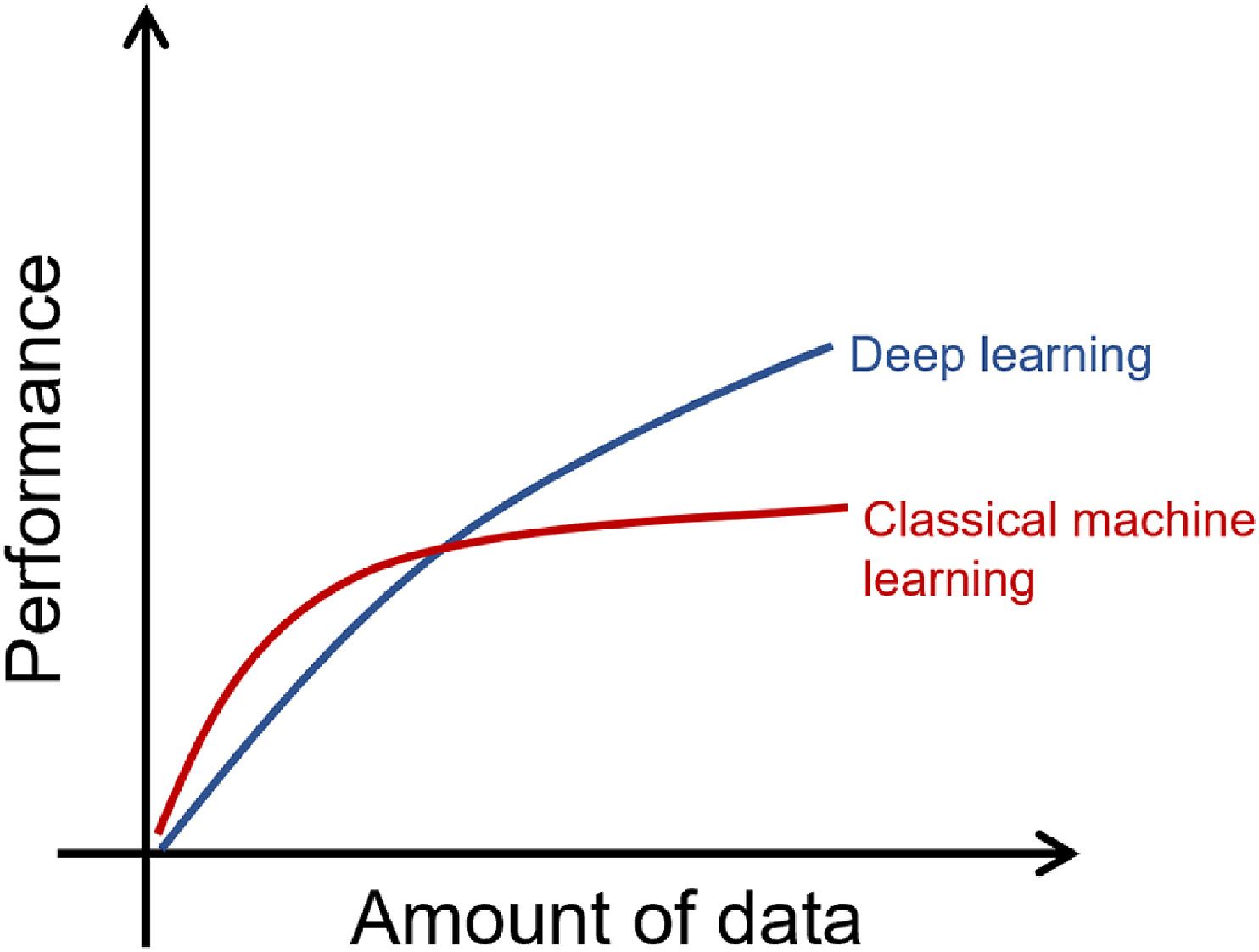
딥 러닝의 가장 대표적인 특징은 확장성이다. 더 많은 데이터를 제공할수록 성능이 향상된다. 수집할 수 있는 데이터의 양에 상한선이 있는 다른 머신 러닝 알고리즘과 다르게 딥 러닝은 이런 제한이 없으며 이론상으로 인간의 이해력을 뛰어넘을 수 있다. 현대의 딥 러닝 기반 이미지 처리 시스템이 인간보다 우수한 성능을 발휘한다는 사실에서 이점은 분명히 드러난다.
딥 러닝의 발전
딥 러닝의 발전 과정을 이야기하려면 우선 인공 지능의 역사를 알아야 한다. 인공 지능의 개념이 세상에 널리 알려지게 된 계기는 1956년 열린 다트머스 컨퍼런스였다. 기계도 생각할 수 있다고 주장한 수학자 앨런 튜링의 연구에서 한 걸음 더 나아가 기계가 인간처럼 학습하고 발전할 수 있는지에 대해 토의가 이루어졌는데, 이때 인공 지능(AI)이란 말도 처음 사용됐다.
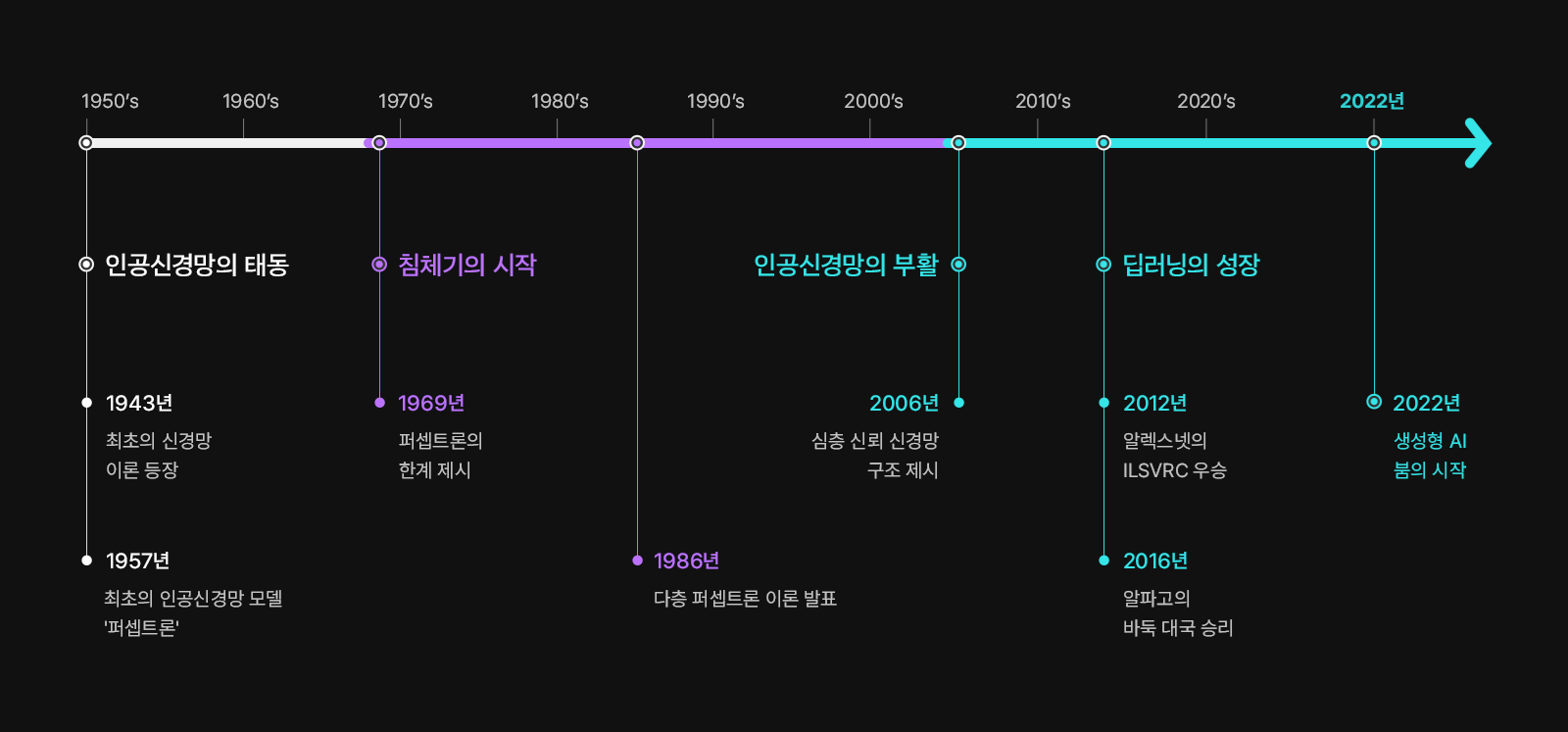
1957년에는 컴퓨터가 패턴을 인식하고 학습할 수 있다는 개념을 실제로 보여준 퍼셉트론(Perceptron) 모델이 프랑크 로젠블랏에 의해 제시됐다. 놀라운 성과에 관련 연구에 대한 기대감도 커졌으나, 부족한 컴퓨팅 성능과 데이터 부족 등 부족한 환경으로 인해 인공 지능 연구는 한동안 침체기에 접어든다.
디지털과 인터넷이 등장한 1990년대부터 인공 지능 연구는 활기를 띠기 시작한다. 연구자의 명령을 통해서만 작동하던 인공 지능이 머신 러닝 알고리즘을 바탕으로 스스로 학습할 수 있게 됐기 때문이다.
딥 러닝의 대부라고 평가받는 제프리 힌튼(Geoffrey Hinton)이 등장한 것도 이 시기다. 제프리 힌튼은 비선형 문제를 해결할 수 없었던 ‘퍼셉트론’ 모델을 인공신경망을 여러 층으로 쌓은 다층 퍼셉트론 모델로 발전시키고 여기에 새로운 알고리즘을 적용해 비선형 문제를 해결할 수 있음을 증명했다. 그리고 2006년에는 다층 퍼셉트론의 성능을 높인 Deep Belief Network(DBN, 심층 신뢰 신경망)를 선보였다. 이를 통해 신경망의 학습 속도와 효율성이 크게 높아졌다.

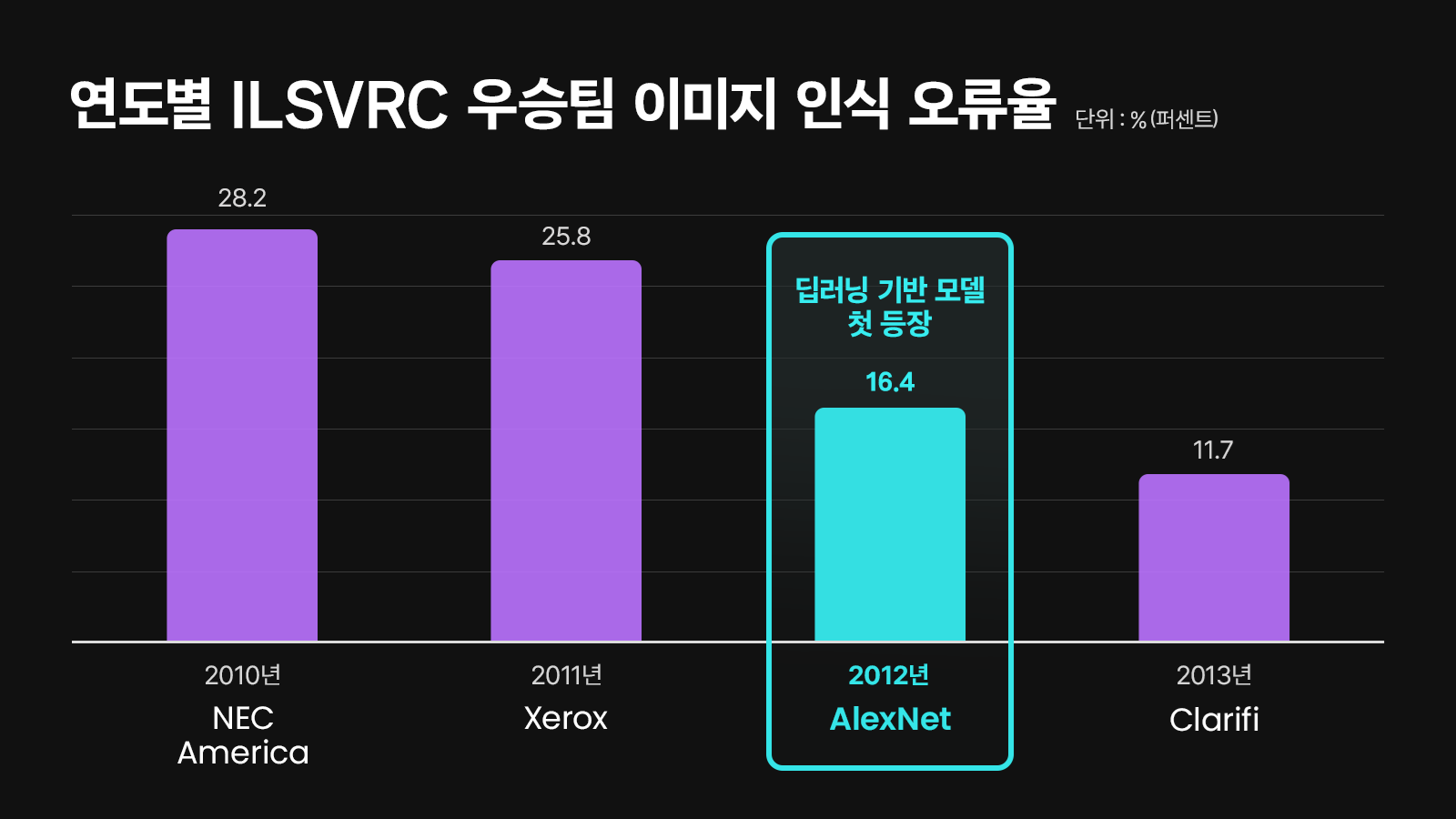
2012년, 제프리 힌튼이 이끄는 알렉스넷팀이 이미지 인식 대회인 ILSVRC에서 압도적인 격차로 우승하면서 딥 러닝의 성능은 주목받기 시작한다. 전년도 우승팀의 이미지 인식 오류율이 25.8%였는데, 알렉스넷은 16.4%에 불과했기 때문이다. 2010년에서 2011년으로 넘어오며 오류율은 2.4% 포인트밖에 줄어들지 않았는데, 알렉스넷은 9.4% 포인트를 줄인 것이니 주목하지 않을 수가 없었다.
그리고 딥 러닝은 2016년 다시 한 번 세계를 놀라게 한다. 구글 딥마인드가 개발한 ‘알파고’가 그 주인공이다. 알파고는 딥 러닝을 바탕으로 머신 러닝 알고리즘 중 하나인 강화 학습, 확률 알고리즘의 하나인 몬테카를로 트리 탐색 알고리즘을 결합해 탄생했다. 그 놀라운 성능은 다들 잘 알고 있을 테니 더 이상의 설명은 생략한다.
대표적인 딥 러닝, 합성곱 신경망
합성곱 신경망(Convolutional Neural Networks, CNN)은 딥 러닝의 대표적인 예다. 이는 시각 피질(시각 입력을 처리하는 뇌 영역)의 뉴런 배치 방식에서 영감을 받았는데, 모든 뉴런이 시각 필드의 모든 입력과 연결되는 건 아니다. 대신 시각 필드는 부분적으로 겹치는 뉴런 그룹(수용 영역이라고도 함)에 채워 넣는다.
합성곱 신경망도 비슷한 방식으로 작동한다. 수학적 합성 연산자를 사용하여 입력의 겹치는 블록을 처리한다. 이는 수용 영역이 작동하는 방식을 근사화한 것이다. 아래 그림(입력된 이미지가 3인지 7인지 구분하는 합성곱 신경망)을 보면서 이어지는 설명을 읽어보자.
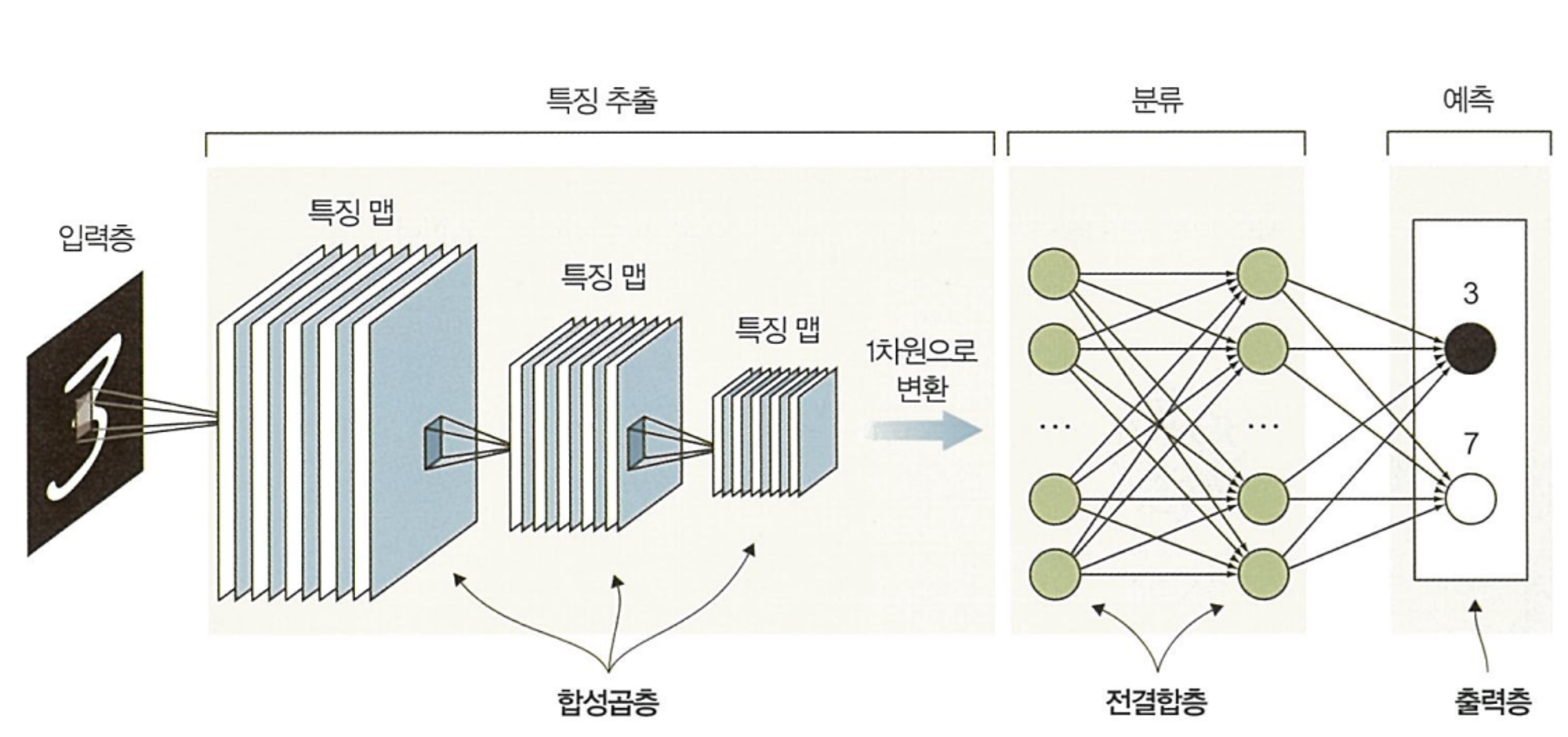
입력한 이미지는 ①첫 번째 합성곱 레이어에서 낮은 수준의 특징을 식별하기 위해 일련의 합성곱 필터를 사용한다. ②추출된 낮은 수준의 특징은 풀링 레이어(Pooling Layer)에서 단순화되어 다음 합성곱 레이어에 입력 이미지로 제공된다. ③다음 레이어는 이전에 식별된 낮은 수준의 특징에서 더 높은 수준의 특징을 식별하기 위해 다른 합성곱 필터 세트를 사용한다.
④이런 과정이 여러 레이어에서 반복되고, 각 합성곱 레이어는 이전 레이어의 입력을 사용해 이전 레이어보다 더 높은 수준의 특징을 식별한다. ⑤그리고 이런 높은 수준의 특징은 전결합층(Fully Connected Layer)에 전달되고, 최종 분류를 위해 모든 특징을 종합한다. ⑥분류된 이미지는 3과 7중에 결과물(예측값)을 출력한다.
이처럼 딥 러닝 모델은 스스로 학습 데이터의 특징을 추출하고, 이를 통해 학습 과정을 진행한다. 이 과정은 아기가 사물을 보고 구분하는 방법과 유사하다고 볼 수 있다. 말이 통하지 않는 아기는 부모의 가르침이 없어도, 즉 인간의 개입이 없어도 다양한 사물을 보고 스스로 구분하는 법을 배우지 않는가.
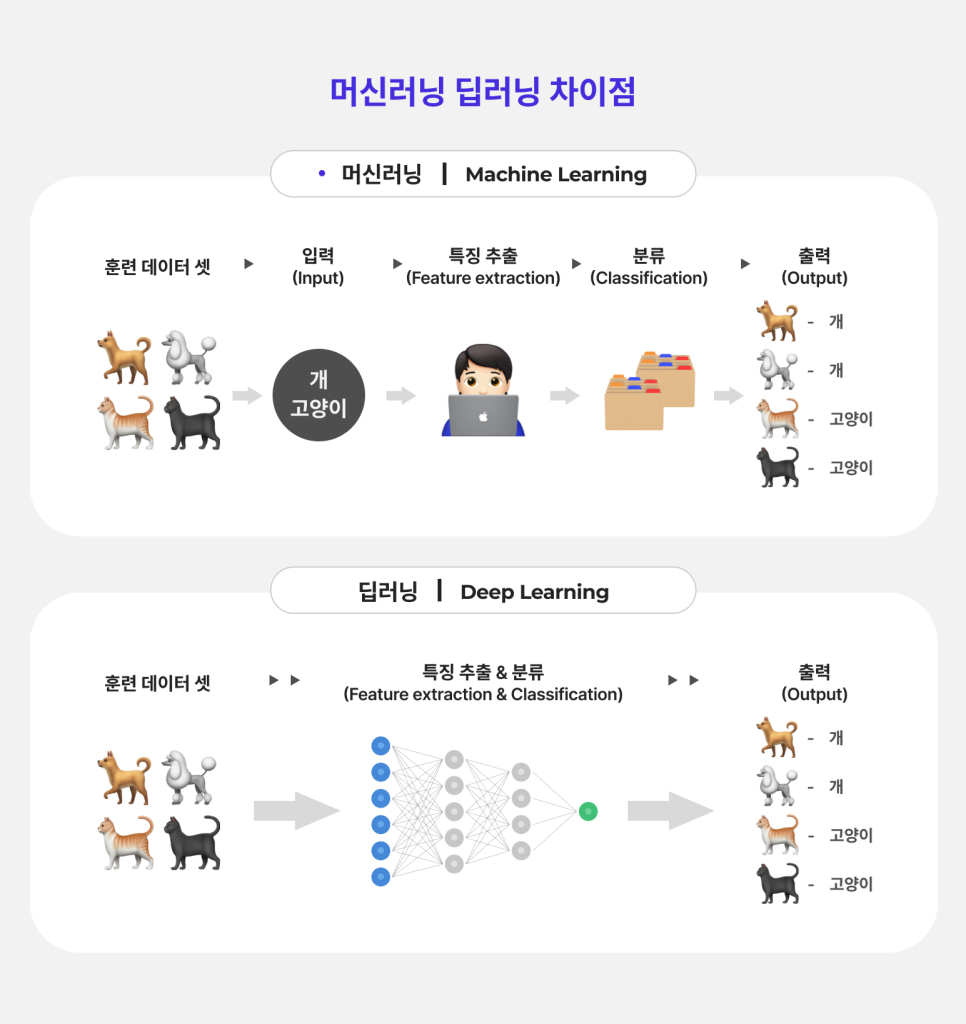
머신 러닝이 개와 고양이 사진에서 연구자가 각 특징을 식별하고 이를 레이블(정답)로 제공한 후 인공 지능이 이를 기반으로 다른 데이터를 분석해 개와 고양이를 분석하는 것과 달리 딥 러닝은 많은 데이터를 통해 스스로 학습하고 이를 통해 개와 고양이를 구분하는 방법을 스스로 찾아내는 것이다.
딥 러닝과 머신 러닝의 관계
우선 포함 관계를 따져 보면, 딥 러닝은 머신 러닝보다 먼저 등장한 개념이긴 하지만, 인공 신경망 개념을 적용한 머신 러닝 기술 중 하나다. 따라서 ‘딥 러닝 ⊂ 머신 러닝 ⊂ 인공 지능’의 포함 관계라고 할 수 있다.

딥 러닝과 머신 러닝의 가장 큰 차이는 사람이 개입하느냐 하지 않느냐다. 머신 러닝은 연구자(사람)가 패턴을 추출하는 방법을 레이블로 제공하고, 인공 지능이 레이블을 기반으로 데이터를 판독하는 반면, 딥 러닝은 인공 지능이 특징을 추출할 수 있도록 신경망을 주고, 인공 지능은 많은 데이터를 기반으로 특징을 종합해 판독하는 것이다.
개와 고양이 사진을 구분하는 과정을 예로 들면, 머신 러닝은 개와 고양이 특징을 사람이 제시해주고 이를 기반으로 사진을 구분하는 것이고, 딥 러닝은 특징을 추출할 수 있는 신경망을 주면 이를 기반으로 인공 지능이 스스로 학습한다고 이해하면 된다.
참고로 딥 러닝의 기술적인 특징으로 계층 학습을 사용하여 먼저 하위 수준의 특징을 식별한 다음 이를 기반으로 상위 수준의 특징을 식별한다는 점에도 주의해야 한다. 보통 합성곱 필터를 사용해 이런 특징을 추출하는데, 하나의 예측 모델이 여러 층으로 구성되어 있더라도 이러한 계층 학습을 사용하지 않는다면 딥 러닝 모델로 인정되지 않는다.